islr notes and exercises from An Introduction to Statistical Learning
6. Linear Model Selection and Regularization
Conceptual Exercises
- Exercise 1: Test and train RSS for subset selection
- Exercise 2: Comparing Lasso Regression, Ridge Regression, and Least Squares
- Exercise 3: How change in affects Lasso performance
- Exercise 4: How change in affects Regression performance.
- Exercise 5: Ridge and Lasso treat correlated variables differently
- Exercise 6: Ridge and Lasso when , , and .
- Footnotes
Exercise 1: Test and train RSS for subset selection
a.
Best subset selection has the most flexibility (searches a larger model space) so it should have the smallest test error for each
b.
The answer depends on the value of . When , FSS yeilds a less flexible model while BSS yeilds a more flexible model, so FSS should have a lower test RSS than BSS. When , the converse shoule be true.
c.
i. True. FSS augments the by a single predictor at each iteration. ii. False. Replace by and this becomes true. iii. False. There is no necessary connection between the models identified by FSS and BSS. iv. False. Same reason. v. False. Best subset considers all possible subsets of predictors so it may include a predictor in that was not in .
Exercise 2: Comparing Lasso Regression, Ridge Regression, and Least Squares
a.
iii. is correct. The Lasso is less flexible since it searches a restricted parameter space (i.e. not ), so it will usually have increased bias and decreased variance.
b.
iii. is correct again, for the same reasons
c.
ii. is correct. Non-linear methods are more flexible which usually means decreased bias and increased variance.
Exercise 3: How change in affects Lasso performance
a. Train RSS
None of these answers seem correct.
For some small , i.e. some -neighborhood , the least squares estimator , hence the Lasso estimator , so . As from below, , so from above. When , so .
In other words, will initially decrease as increases, until catches , and thereafter it will remain constant . The closest answer is iv., although “steadily decreasing” isn’t the same thing.
A better answer would be iv. then v..
b. Test RSS
ii. Test RSS will be minimized at some optimal value of and will be greater for (lower flexibility and bias outweighs variance) and (higher flexibility and variance outweighs bias)1.
c. Variance
iii. We expect variance to increase monotonically with model flexibility.
d. (Squared) Bias
iv. We expect bias to decrease monotonically with model flexibility.
e. Irreducible Error
v.. The irredicible error is the variance of the noise which is not a function of .
Exercise 4: How change in affects Regression performance.
For this exercise, we can observe that (that is, model flexibility increases as increases) and that our answers will be unaffected by whether we use the norm (Lasso) or norm (Ridge), so we can use the same reasoning as in exercise 3
a. Train RSS
v. then iii.
b. Test RSS
ii.
c. Variance
iv.
d. Irreducible Error
v.
Exercise 5: Ridge and Lasso treat correlated variables differently
For this exercise we have data
a. The ridge optimization problem
The ridge regression problem in general is
For this problem
so we have the optimization problem
b. The ridge coefficient estimates
Since we know , we have the (slightly) simpler problem
write for this objective function we are trying to minimize 2. Taking partial derivatives and setting equal to zero
Subtract the first equation from the second and collect terms. Since by assumption 2 ) we can divide through by to find , hence 3
c. The lasso optimization problem
The lasso regression problem in general is
For this problem RSS is the same as for part b
so we have the optimization problem
d. The lasso coefficient estimates
Again, since we know , we have the (slightly) simpler problem
again write for this objective function.
It is somewhat difficult to argue analytically that this function has no unique global minimum, so we’ll look at some graphs
Visualizing some examples
Here we’ll graph the objective function for the case to get a sense of what’s going on:
from mpl_toolkits import mplot3d
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
(x, y, lambda_) = (1, 1, 1)
beta_1 = np.linspace(-6, 6, 30)
beta_2 = beta_1
X, Y = np.meshgrid(beta_1, beta_2)
Z = np.square(y - (X + Y)*x) + lambda_*(np.absolute(X) + np.absolute(Y))
fig = plt.figure(figsize=(15, 15))
ax = plt.axes(projection='3d')
ax.plot_surface(X, Y, Z, rstride=1, cstride=1,
cmap='gray', edgecolor='none')
<mpl_toolkits.mplot3d.art3d.Poly3DCollection at 0x116a7a208>
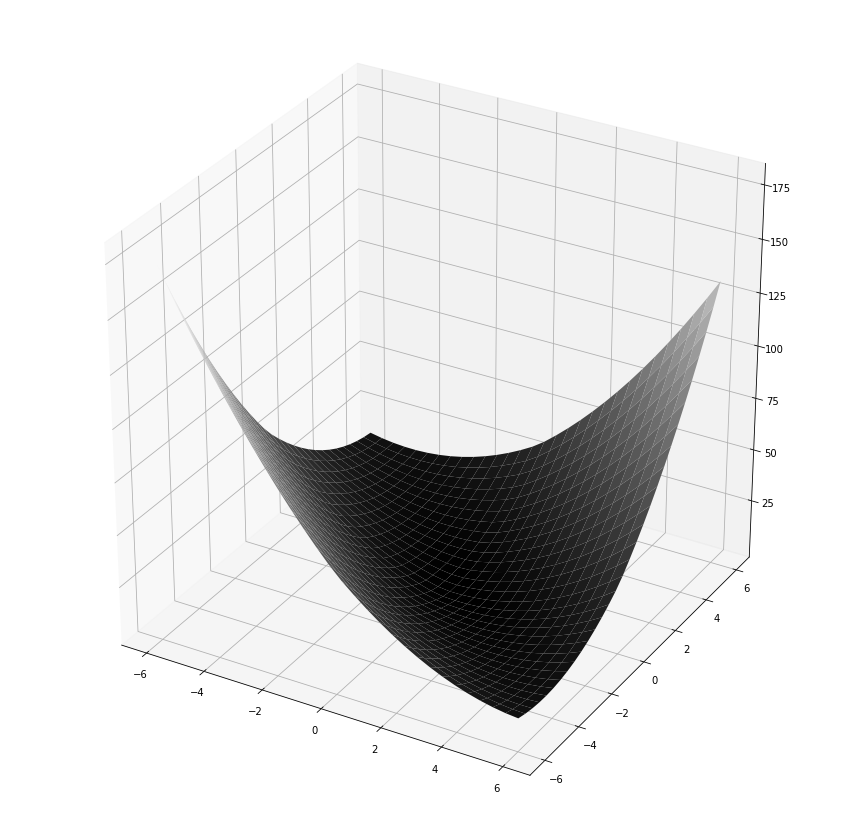
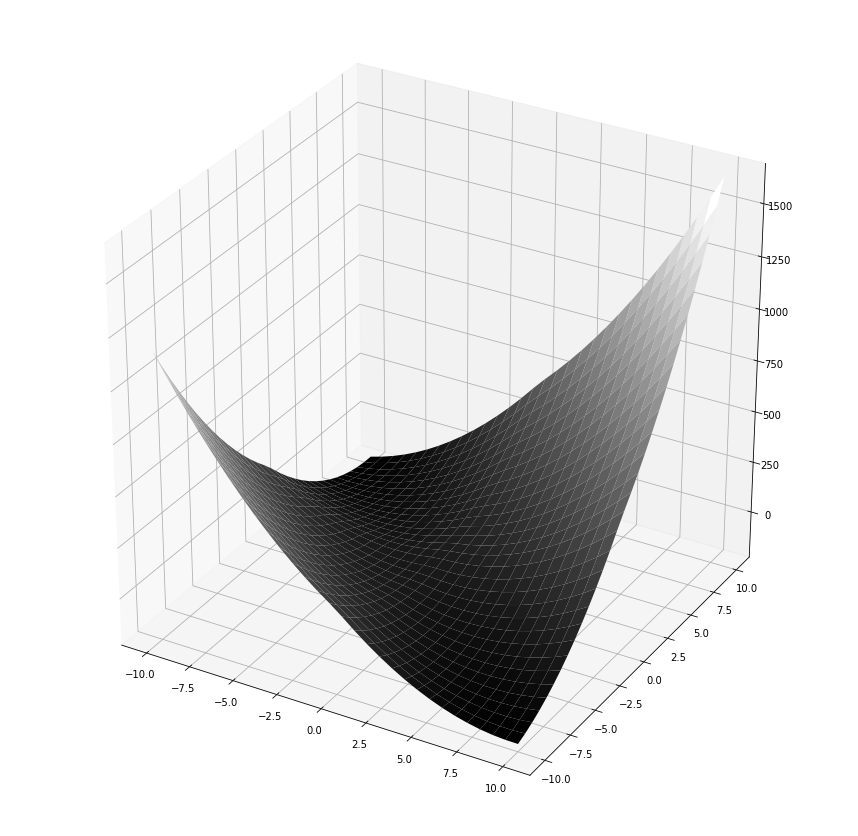
ax.view_init(0, 60)
fig
###
It’s difficult to see from this picture, but it appears that minimum of this graph is , which is uninteresting.
Now let’s look at
(x, y, lambda_) = (-2, 3, 10)
Z = np.square(y - (X + Y)*x) - lambda_*(np.absolute(X) + np.absolute(Y))
fig = plt.figure(figsize=(15, 15))
ax = plt.axes(projection='3d')
ax.plot_surface(X, Y, Z, rstride=1, cstride=1,
cmap='gray', edgecolor='none')
<mpl_toolkits.mplot3d.art3d.Poly3DCollection at 0x114292e10>
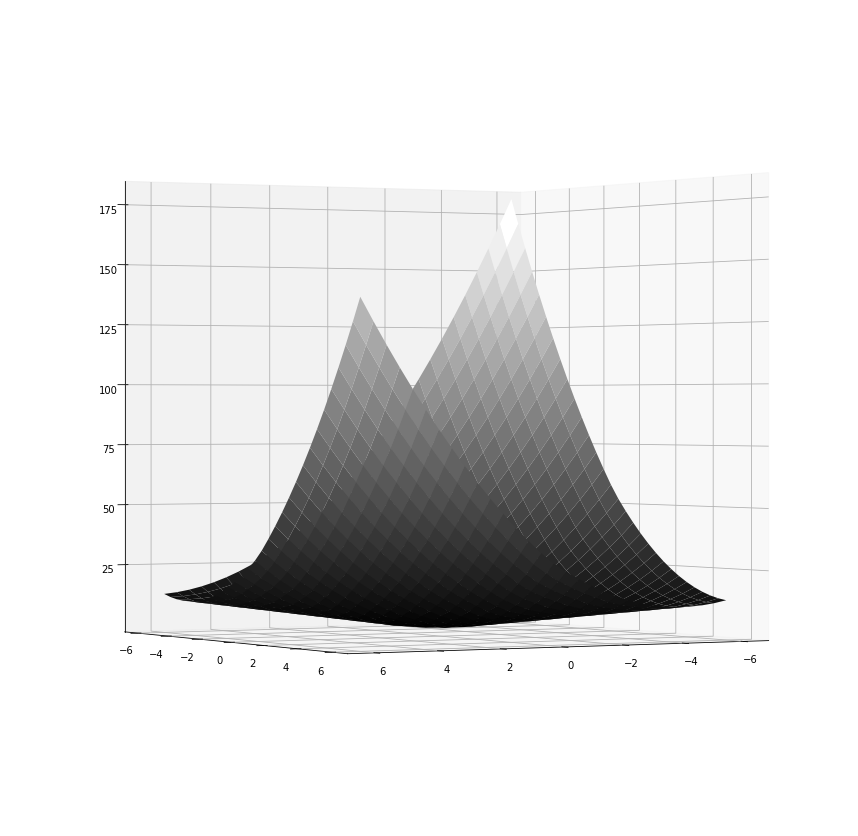
ax.view_init(0, 60)
fig
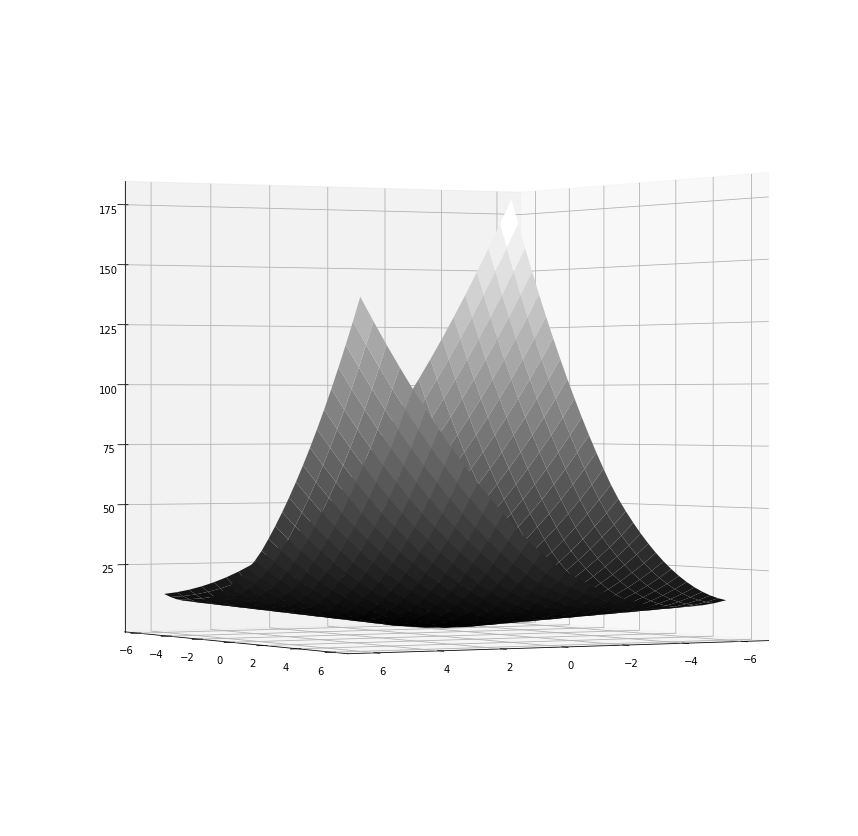
Now we can see no global minimum whatsoever
Arguing analytically
The graphs above have suggested no global minimum exists, so let’s see if we can argue that analytically.
Observe that, since is a piecewise function, is. Thus we can minimize by minimizing each of
and then taking the minimum over all of these 4.
This corresponds to find
Minimizing and .
Taking partial derivatives 5 of and setting equal to zero
these equations are redundant, so we find a minimum for whenever:
Similarly, we find a minimum for whenever:
Minimizing ,
Taking partial derivatives and setting equal to zero
Subtracting the first equation from the second and doing some algebra, we find , which is a case we’re not considering.
Now, focusing on the first equation, we conlude is strictly decreasing for as long as
This inequality is always satisfied for some values of , so we conclude that, provided , is always strictly decreasing along some direction.
Conclusions
Exactly one of the following is true:
-
, in which case a global minimum of exists but we are doing trivial lasso regression (i.e. just ordinary least squares).
-
, in which case no global minimum of exists.
Thus, if we are looking for non-trivial lasso coefficient estimates, we cannot find unique ones 6
Exercise 6: Ridge and Lasso when , , and .
a. Ridge regression
Consider (6.12) in the case . Then the minimization problem becomes
Now we plot for the case
lambda_,y = 1, 1
X = np.linspace(-5, 5, 30)
Y = np.square(1 - X) + np.square(X)
plt.plot(X, Y)
[<matplotlib.lines.Line2D at 0x1175ac438>]
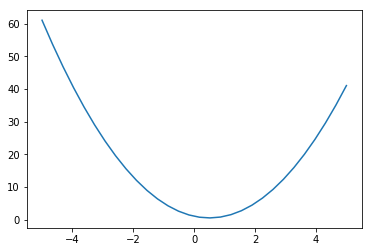
It’s easy to believe that the minimum is at the value given by (6.14):
b. Lasso regression
Consider (6.13) in the case . Then the minimization problem becomes
Now we plot for the case
lambda_,y = 1, 1
X = np.linspace(-5, 5, 30)
Y = np.square(1 - X) + np.absolute(X)
plt.plot(X, Y)
[<matplotlib.lines.Line2D at 0x11775ada0>]
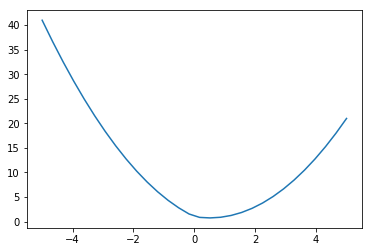
It’s easy to believe that the minimum is at the value given by (6.15):
Exercise 7: Deriving the Bayesian connection between Ridge and Lasso
a. Likelihood for the linear model with Gaussian noise
We assume
where iid 7.
The likelihood is 8
b.
c.
d.
e.
Footnotes
-
For evidence, we can observe that , and look at Figure 6.8 as a typical example. ↩
-
We know that will give a minimum, but then we just have the least squares solution. So assuming is determined by other means (e.g. cross validation), our objective function shouldn’t depend on . ↩ ↩2
-
Note that, even though we know the ridge regression coefficient estimates are equal, they aren’t unique. So there are still “many possible solutions to the optimization problem”. ↩
-
That is, find the minima of in each of the four quadrants of the plane and take the minimum over the quadrants. ↩
-
Strictly speaking, we are taking “one-sided derivatives”. ↩
-
This is presumably what the book means by “many possible solutions to the optimization problem”. ↩
-
As usual, , and the first column of is . ↩
-
This follows, since the random variable conditioned on the random variates is , and from it follows that . ↩