islr notes and exercises from An Introduction to Statistical Learning
5. Resampling Methods
Conceptual Exercises
Exercise 1: Minimize the weighted sum of two random variables
Using basic statistical properties of the variance, as well as single- variable calculus, derive (5.6). In other words, prove that α given by (5.6) does indeed minimize Var
Using properties of variance we have
Taking the derivative with respect to , set to zero
solve for to find
Exercise 2: Derive the probability an observation appears in a bootstrap sample
a.
What is the probability that the first bootstrap observation is not the jth observation from the original sample? Justify your answer.
Since the boostrap observations are chosen uniformly at random
b.
What is the probability that the second bootstrap observation is not the jth observation from the original sample?
The probability is still since the bootstrap samples are drawn with replacement
c.
Let
Then since the bootstrap observations are drawn uniformly at random the are independent and hence
d.
We have
So
When ,
1 - (1 - 1/5)**5
0.6723199999999999
e.
When is
1 - (1 - 1/100)**100
0.6339676587267709
f.
When is
1 - (1 - 1/10e4)**10e4
0.6321223982317534
g.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('seaborn-white')
x = np.arange(1, 100000, 1)
y = 1 - (1 - 1/x)**x
plt.plot(x, y, color='r')
[<matplotlib.lines.Line2D at 0x11d180860>]
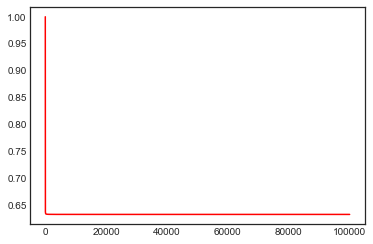
The probability rapidly drops to around
x = np.arange(1, 10, 1)
y = 1 - (1 - 1/x)**x
plt.plot(x, y, color='r')
[<matplotlib.lines.Line2D at 0x121806ac8>]
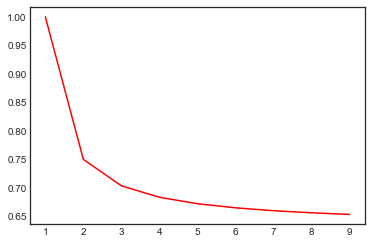
then slowly asymptotically approaches the limit
h.
data = np.arange(1, 101, 1)
sum([4 in np.random.choice(data, size=100, replace=True) for i in range(10000)])/10000
0.6308
Very close to the expected value of
1 - (1 - 1/100)**100
0.6339676587267709
Exercise 3: -fold Cross Validation
See section 5.1.3 in the notes
Exercise 4: Estimate the standard deviation of a predicted reponse
Suppose given we predict . This is an estimator [^0]. To estimate its standard error using data use the “plug-in” estimator 1.
where is the predicted value for and is the mean predicted value.
In other words, use the sample standard deviation of the predicted values.
Footnotes
0. ↩
-
An estimator is a statistic (a function of the data) used to estimate a population quantity – it is a random variable corresponding to the statistical learning method we use and dependent on the observed data. ↩